

The need for complex, multilingual analyses has increased following the Paris Agreement; machine learning algorithms are making it a reality.
While many organizations are seeking to reap the benefits of AI in their data collection and analysis initiatives, it is within the environmental industry that we at Arboretica are seeing some of the biggest – and most immediate – impacts from the technology.
Since the adoption of the Paris Agreement in 2015, organizations within the environmental industry have seen increased demand for regular monitoring and reporting on governmental commitments on a wide range of ESG topics. As regional groups, city governments, and businesses make their own commitments, the need for policy analysis is growing exponentially.
Challenges in Current State of Environmental Policy Analysis
Current Data Collection Approach Is Time-Consuming
Many organizations rely upon teams of people to manually complete research, a labor-intensive process that often requires a never-ending cycle of Google searches, article review, and disparate Excel “databases” due to an increasing number of entities to be reviewed and ever-changing policy updates. Coupled with language barriers, the task of data collection and analysis can seem almost insurmountable: it requires hours of manpower, teams with fluency across multiple languages, and it is accompanied by the risks of human error or oversight.
Resource-Consuming Data Collection Limits Scope of Analysis
Organizations limit the type of analysis they undertake knowing the challenges of manual data collection. For example, to save time and leverage existing resources, an organization might focus on monitoring environmental policy changes of five big countries instead of undertaking a global, multi-lingual analysis. Organizations do not dare dream of large-scale, in-depth analyses because of the hurdles of data collection.
Time Constraints Become Apparent With Exponential Increase in Policy Analysis Needs
The need for environmental policy analysis is growing exponentially. The Paris Agreement sparked country-level environmental policies and has had a knock-on effect on policies at regional, city, and business levels. As the number of policies increase, manual analysis is a herculean effort. What’s more, the effort is not finite: policy changes, so analyses need to be updated regularly.
Ultimately, the current approach to environmental policy analysis is not a sustainable long-term solution. Arboretica’s new technology methodology can provide a more efficient and effective way.
Arboretica’s Technology Offers a New Approach to Accelerate Data Collection and Unlock Data Analysis Possibilities
At Arboretica, we’ve put the power of AI to work in streamlining the entire policy analytics process. We emphasize the power of the machine to augment manual work, NOT replace it, ultimately doing more, faster, and with fewer human resources.
We build algorithms that replicate how we humans think. When data collection is done manually, people are reading for certain keywords, repetitive patterns, key data such as dates or timeframes, and so much more. Our algorithms are built to mimic that.
Our Five-Step Process to Developing a Powerful Environmental Policy Algorithm
Step 1: Training the algorithm with sample data
Using sample policy data, we “train” the machine not only to seek key data, but to begin to understand the distinctions between words or phrases that may make all the difference in relevance to reporting.
For example, the word “offset” in “offset carbon emissions” may come up in many contexts. We help the algorithm understand the desired use cases of the term.
Step 2: Assessing the scale of data
Our algorithms are able to accommodate a massive volume of data, and can scan millions of web pages for one single project. During this step, we identify just how much data the algorithm will have to analyze. To do so, we look at four elements:
- Time frame: When was the relevant data produced? (For example, post-Paris Agreement)
- Language: In what languages will the algorithm find relevant data? (For example, only English-language sources)
- Number of entities: Which countries’ or sub-countries’ policies should the algorithm review? (For example, only EU-member countries)
- Number of sub-topics: Which environmental sub-topics are relevant? (For example, deforestation policy)
We teach the algorithms to accommodate the different languages or additional subtopics required by the policy analysis. Each variation requires modifications to the algorithms and additional “training” to learn what information is important and what can be discarded.
Step 3: Data compilation and extraction
Once the algorithms are complete, we set them in motion, setting up queries to scour public data sources to collect information. Our technology then goes a step beyond typical data collection and uses natural language processing to extract from the search only the data that is relevant to the analysis – identifying the sentences or paragraphs with relevant keywords so that humans do not need to read an entire book to find the most appropriate passage.
In a recent engagement, our algorithms searched more than 1 million different URLs for 175 countries, found 600,000 candidate articles, extracted and identified 269 unique, accurate policies from 93 countries by machine – and saved teams of researchers from reading each and every policy document.
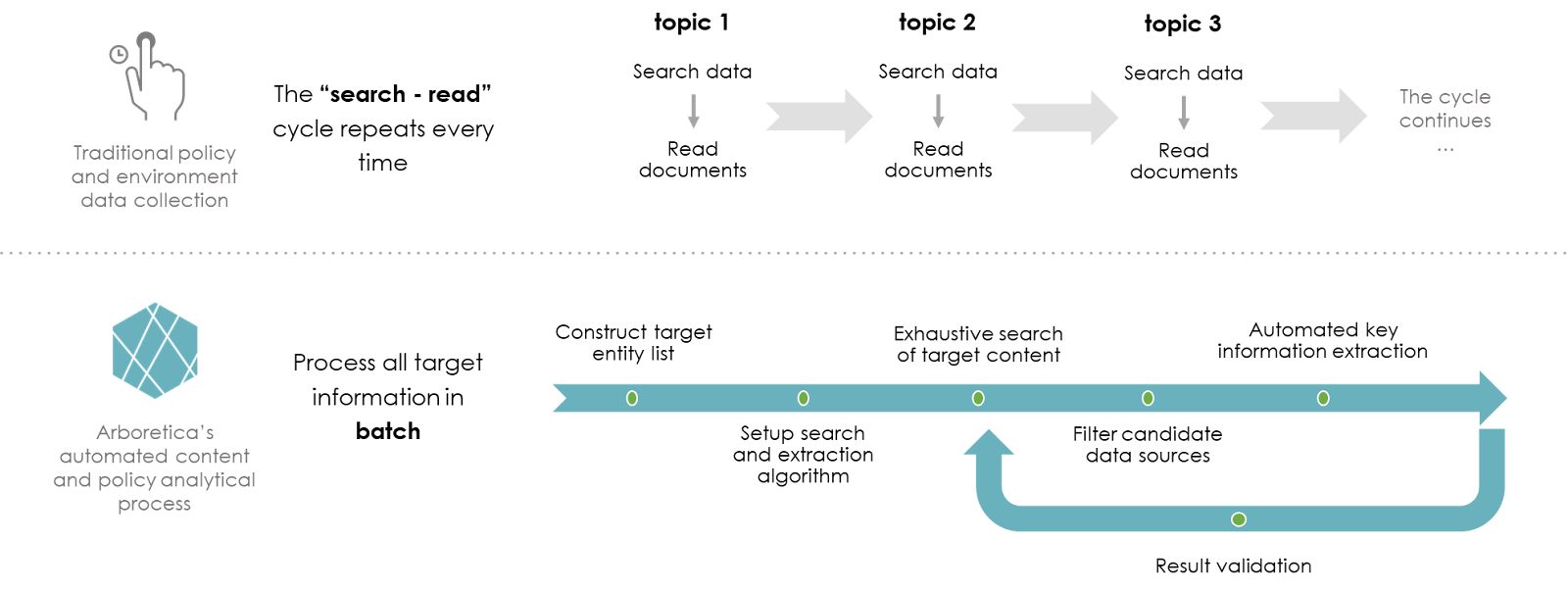
Step 4: Human validation of data collected
At that point, humans step back in to look at the algorithm’s results. We work with our client teams to validate that the information collected is accurate and relevant; or, that it’s not. (Even in the case of invalid data collection, it’s better to “fail faster” and course correct, refining the algorithm to capture the relevant data, than invest hours of manpower in manually collecting the wrong information!)
Step 5: Iterating and improving the algorithm
We take the client team’s feedback and use that to train the algorithm again. As the algorithm iterates, it gets smarter and accuracy increases, eventually further reducing the time needed for manual human validation.
The Advantages of AI in Environmental Policy Analysis
Arboretica’s machine-learning algorithms produce ongoing, repeatable, accurate data collection – a near impossibility to achieve with manual effort. And especially within the environmental landscape, heavy with NGOs and universities that have rapid turnover and challenges with knowledge transfer, AI-powered policy analysis guarantees the continuity of data collection and assessment.
And ultimately, the results speak for themselves. On a recent policy tracker engagement, use of Arboretica’s algorithms enabled researchers to achieve:
- A 90% reduction in time spent reading and processing policies
- A 100x increase in the policy sources collected
- And a 66% decrease in overall manpower required to collect and analyze policy data

These are the types of results that can only be achieved through technology and automation. And we’re thrilled to develop solutions that empower organizations to achieve those previously out-of-reach objectives.
If your organization can benefit from the power of Arboretica’s AI solutions, contact us today.
